Build recommendation system using Scala, Spark and Hadoop
Table of Contents
- Table of Contents
- 1. Introduction to recommendation system
- 2. System setup
- 3. Dataset
- 4. Runnning in Spark
- 5. Running PySpark version in Databricks
- 6. Recommendation system design
- 7. Implementation
- 8. Summary
- Contact
Recommendation system is a widely used machine learning technique that has many applications in E-commerce (Amazon, Alibaba), video streaming (Netflix, Disney+), social network (Facebook, Linkedin) and many other areas. Because of the large amount of data in those services, nowadays most of industry-level recommendation systems are built in big data frameworks like Spark and Hadoop. So in this blog I want to show you how I built a movie recommendation system using Scala, Spark and Hadoop.
(This article was also published on Towards Data Science.)
1. Introduction to recommendation system
1.1 Different recommendataion system algorithms
Recommendataion system algorithms can be categorized into two main types: content-based recommendation and collaborative filtering. Below is a summary table describing their differences.
| Content-based recommendation | Collaborative filtering | |
|---|---|---|
| Description | Utilizes product characteristics to recommend similar products to what a user previously liked. | Predicts the interest of a user by collecting preference information from many other users. |
| Assumption | If person P1 and person P2 have the same opinion on product D1, then P1 is more likely to have the same opinion on product D2 with P2 than with a random chosen person Px. | If person P likes product D1 which has a collection of attributes, he/she is more likely to like product D2 which shares those attributes than product D3 which doesn’t. |
| Example | news/article recommendation | movie recommendation, Amazon product recommendation |
| Advantages | - The model doesn’t need any user data input, so easier to scale. - Capable of catching niche items with feature engineering. |
- No domain knowledge needed, highly transferrable model. - Capable of helping users discover new interests. |
| Disadvantages | - Requires domain knowledge. - Limited ability to expand user’s interests. |
- Cold-start problem: need to work with existing data, can’t handle fresh items/users. - Difficulty in expanding features for items. |
1.2 Collaborative filtering and Spark ALS
In this post, we will use collaborative filtering as the recommendation algorithm. How collaborative filtering works is this: First, we consider the ratings of all users to all items as a matrix, and this matrix can be factorized to two separate matrices, one being a user matrix where rows represent users and columns are latent factors; the other being a item matrix where rows are latent factors and columns represent items (see figure below). During this factorization process, the missing values in the ratings matrix can be filled, which serve as predictions of user ratings to items, and then we can use them to give recommendations to users.
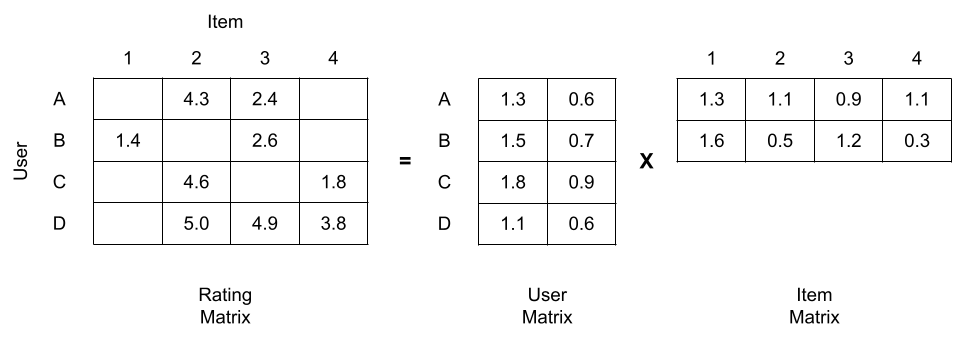
Matrix factorization in collaborative filtering
ALS (alternating least squares) is a mathematically optimized implementation of collaborative filtering that uses Alternating Least Squares (ALS) with Weighted-Lamda-Regularization (ALS-WR) to find optimal factor weights that minimize the least squares between predicted and actual ratings. Spark’s MLLib package has a built-in ALS function, and we will use it in this post.
2. System setup
- Ubuntu 20.04.3
- JDK 11.0.13
- Scala 2.12.11
- Spark 3.2.0
- Hadoop 3.2.2
- IntelliJ IDEA (2021.3.1)
For detailed setup of system prerequisites, follow my previous post.
3. Dataset
In this project we will use the MovieLens dataset from University of Minnesota, Twin Cities. You can download ml-100k (4.7M) by running:
wget https://files.grouplens.org/datasets/movielens/ml-100k.zip
Unzip the zip file by running:
unzip ml-100k.zip
You will see unzipped ml-100k folder contain multiple files.

We mainly use two data files:
u.data: user ratings data, includes user id, item id, rating, timestamp.u.item: movies data, includes item id, movie title, release date, imdb url, etc.
4. Runnning in Spark
4.1 Clone code from Github
Before running in Spark, clone code from my Github Repository to your local directory using:
git clone https://github.com/haocai1992/MovieRecommender.git
Open the folder in IntelliJ IDEA. Your project structure should look like this:
4.2 Preparing data in HDFS
Befofe we start, we need to start hadoop HDFS and YARN services in terminal (see how in this post).
$ hadoop namenode -format
$ start-all.sh
Then we need to upload ml-100k dataset to Hadoop HDFS:
$ hadoop fs -put ~/Downloads/ml-100k /user/caihao/movie
4.3 Train recommendataion model in Spark
Train a recommendation model in Spark using:
$ spark-submit --driver-memory 512m --executor-cores 2 --class RecommenderTrain --master yarn --deploy-mode client ~/Desktop/spark_test/MovieRecommender/out/artifacts/MovieRecommender_jar/MovieRecommender.jar
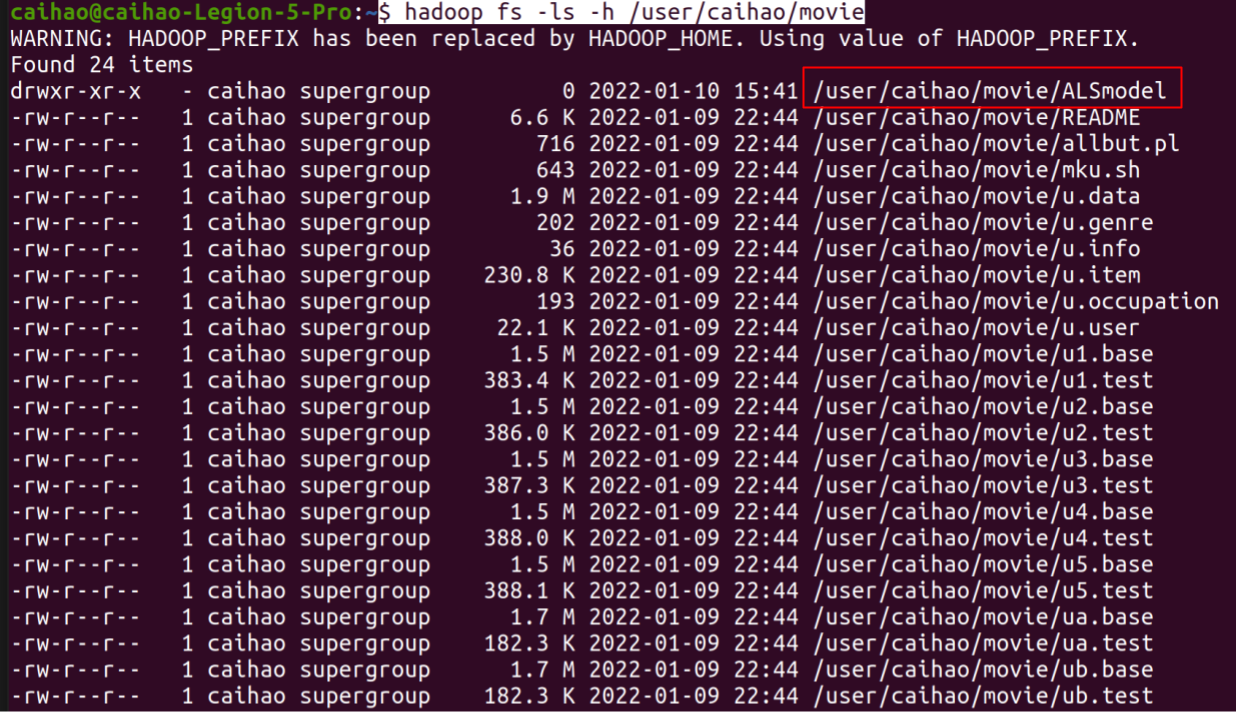
Check out your trained model in HDFS using:
$ hadoop fs -ls -h /user/caihao/movie
You will see your model here:
4.4 Generating recommendations in Spark
Recommend movies for userID=100 in Spark using:
$ spark-submit --driver-memory 512m --executor-cores 2 --class Recommend --master yarn --deploy-mode client ~/Desktop/spark_test/MovieRecommender/out/artifacts/MovieRecommender_jar2/MovieRecommender.jar --U 100
You will see this output:
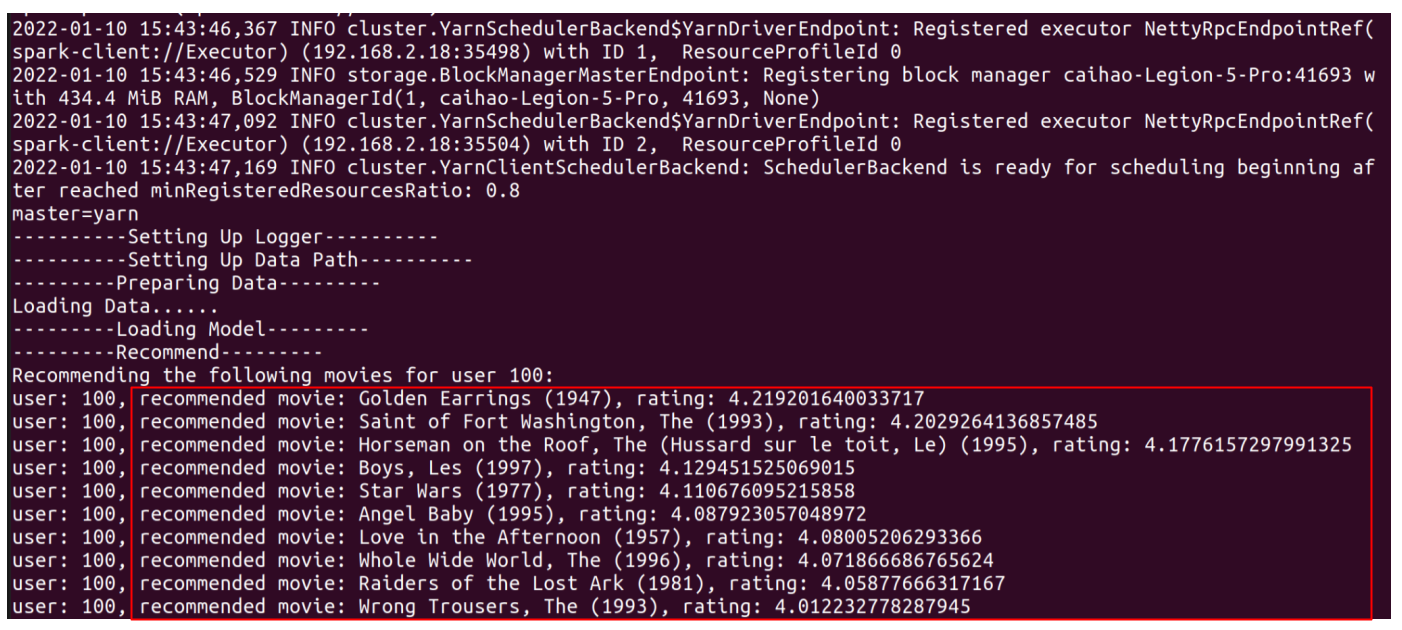
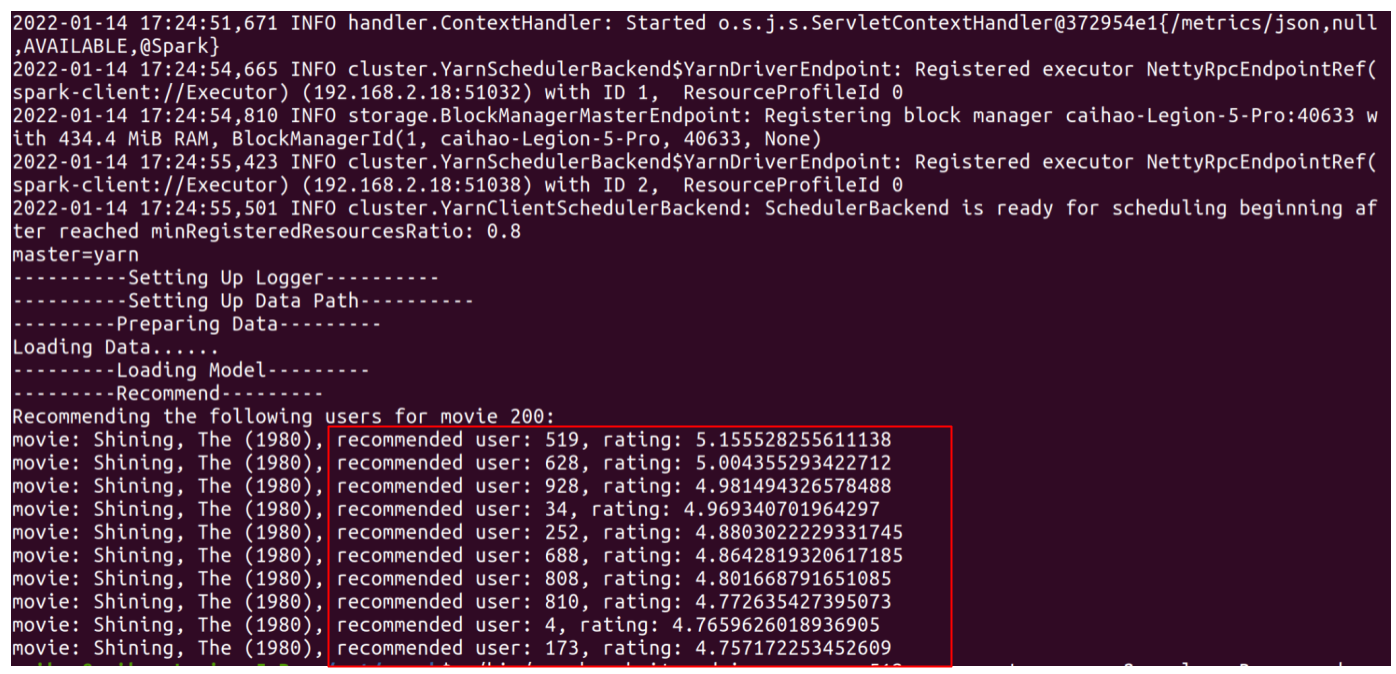
Or recommend users for movieID=200 in Spark using:
./bin/spark-submit --driver-memory 512m --executor-cores 2 --class Recommend --master yarn --deploy-mode client ~/Desktop/spark_test/MovieRecommender/out/artifacts/MovieRecommender_jar2/MovieRecommender.jar --M 200
You will see this output:
5. Running PySpark version in Databricks
If you don’t know Scala, I also created a Python version of the recommendation system! It’s using PySpark and runs on Databricks.
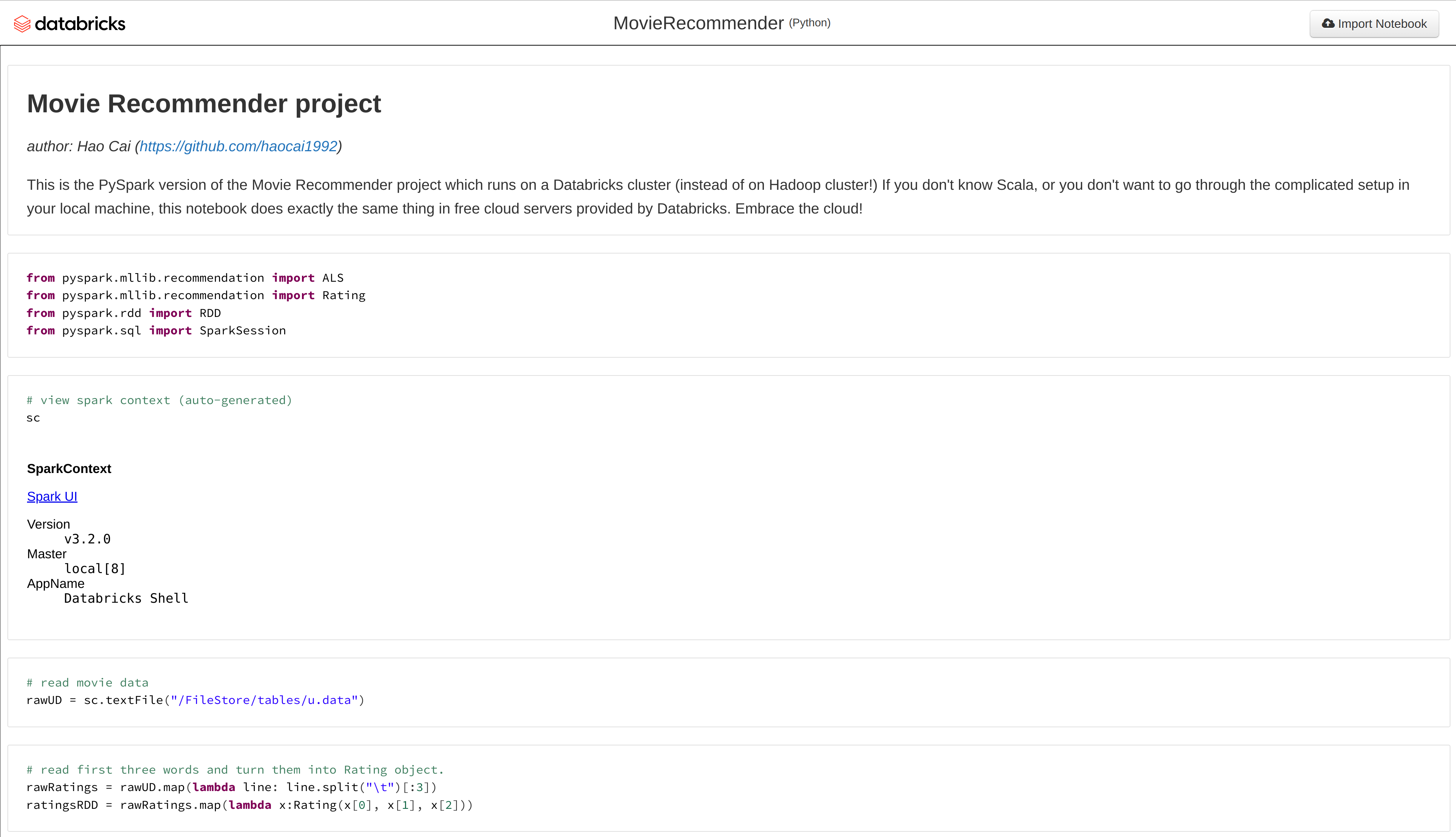
Check my code here: my Databricks notebook.
To find out more about how to create a cluster on Databricks and run Spark, check out this tutorial.
6. Recommendation system design
Our system design are as below.
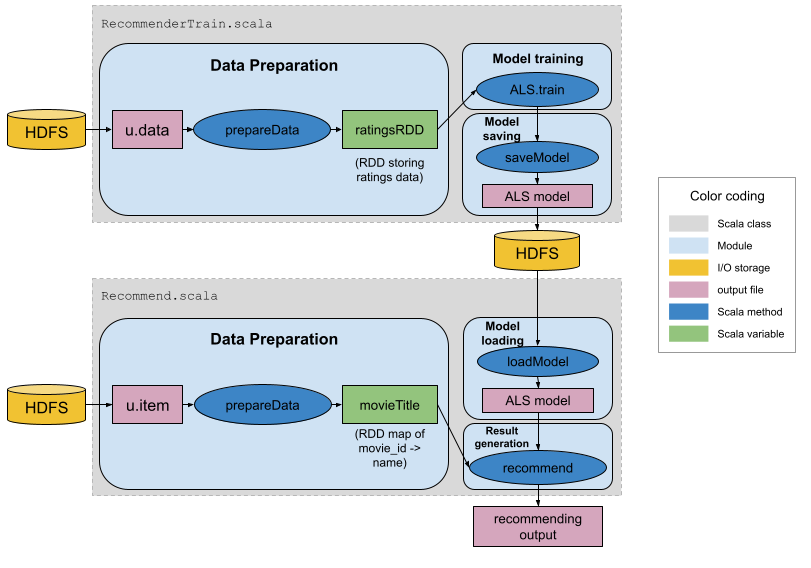
In summary, there are two Scala objects:
RecommenderTrain.scala: reads ratings file (u.data), prepares data, trains ALS model and saves model.Recommender.scala: reads movies file (u.item), loads ALS model, generating movie recommendations.
7. Implementation
7.1 Training ALS model - RecommenderTrain.scala
RecommenderTrain.scala is a Scala object that contains three main methods.
7.1.1 prepareData
prepareData reads ratings data from path, parses useful fields and returns ratingsRDD.
def PrepareData(sc: SparkContext, dataPath:String): RDD[Rating] = {
// reads data from dataPath into Spark RDD.
val file: RDD[String] = sc.textFile(dataPath)
// only takes in first three fields (userID, itemID, rating).
val ratingsRDD: RDD[Rating] = file.map(line => line.split("\t") match {
case Array(user, item, rate, _) => Rating(user.toInt, item.toInt, rate.toDouble)
})
println(ratingsRDD.first()) // Rating(196,242,3.0)
// return processed data as Spark RDD
ratingsRDD
}
7.1.2 ALS.train
ALS.train does explicit rating training of ratingsRDD and returns a MatrixFactorizationModel object.
val model: MatrixFactorizationModel = ALS.train(ratings=ratingsRDD, rank=5, iterations=20, lambda=0.1)
Information about training parameters:
| Parameter | Description |
|---|---|
| ratings | RDD with a format of Rating(userID, productID, rating) |
| rank | during matrix generation, the original matrix A(m x n) is decomposed into X(m x rank) and Y(rank x n), in which rank essentially means the number of latent factors/features that you can specify. |
| iterations | number of ALS calculation iterations (default=5) |
| lambda | regularization factor (default=0.01) |
7.1.3 saveModel
saveModel saves model to path.
def saveModel(context: SparkContext, model:MatrixFactorizationModel, modelPath: String): Unit ={
try {
model.save(context, modelPath)
}
catch {
case e: Exception => println("Error Happened when saving model!!!")
}
finally {
}
}
}
7.2 Generating recommendations - Recommend.scala
Recommend.scala is a Scala object that contains four main methods.
7.2.1 prepareData
prepareData reads movies data from path, parses useful fields and returns movieTitle.
def prepareData(sc: SparkContext, dataPath:String): RDD[(Int, String)] ={
println("Loading Data......")
// reads data from dataPath into Spark RDD.
val itemRDD: RDD[String] = sc.textFile(dataPath)
// only takes in first two fields (movieID, movieName).
val movieTitle: RDD[(Int, String)] = itemRDD.map(line => line.split("\\|")).map(x => (x(0).toInt, x(1)))
// return movieID->movieName map as Spark RDD
movieTitle
}
7.2.2 MatrixFactorizationModel.load
MatrixFactorizationModel.load loads ALS model from path.
val model: MatrixFactorizationModel = MatrixFactorizationModel.load(sc=sc, path=modelPath)
7.2.3 model.recommendProducts
model.recommendProducts recommends movies for given userID.
val recommendP = model.recommendProducts(user=inputUserID, num=10)
7.2.4 model.recommendUsers
model.recommendUsers recommends users for given itemID.
val recommendU = model.recommendUsers(product=inputMovieID, num=10)
8. Summary
And there you go, we have built a recommendataion system using Scala + Spark + Hadoop (with PySpark + Databricks), Congratulations! I hope you found this post useful.
Contact
- Author: Hao Cai
- Email: haocai3@gmail.com
- Github: https://github.com/haocai1992
- Linkedin: https://www.linkedin.com/in/haocai1992/